It’s not a really secret, but I try not to advertise this.
I watch ASMR. A lot.
Sometimes in the evening, to wind down. Other times at night when I can’t sleep. But most often during the workdday, to provide quiet background noise while I work.
I favor pretty vanilla ASMR–quiet tapping, people doing tasks slowly and with intention, massage, skincare. But occasionally the Youtube algorithm leads me into scary, scary spaces filled with people sucking on fake ears and sexily eating live seafood.
Naturally, I had to map these strange byways of the internet.
Welcome to the ASMRiverse.
ASMR content creators
Youtube hosts most, but not all, of the ASMRiverse. I personally consume all my ASMR content there. For simplicity, I decided to focus my mapping efforts solely on ASMR videos on Youtube.
Google is extremely stingy with their Youtube API limits, so I had to choose what to map carefully. Although I would have liked to include as many content creators (“ASMRtists”) in the map as I could physically find, it just wasn’t feasible.
Instead, I limited myself to channels that met the following criteria:
- Had at least 25,000 subscribers
- Had at least 5 videos in their top 10 most popular videos that looked to be ASMR-related
- ASMR related videos are ones that contain the words ASMR, whisper, or soft-spoken in their title or description
That led me to a roster of 1837 Youtube channels.
Next, I wanted to see how these channels related to one another. For this I turned to videos. If one channel’s videos frequently appeared in another channel’s videos’ “related” section, I figured those two channels were probably fairly similar in terms of audience and content.
Finally, once I had a big list of how similar each channel was to every other channel, I could group them into genres and subgenres. This is where it gets kind of technically hairy, so details are the bottom. Suffice it to say I fed the list into an algorithm and it popped out a bunch of genres.
And, finally, here we are. A candy-colored map of the ASMRiverse, sorting each channel into a genre and subgenre. Please enjoy.
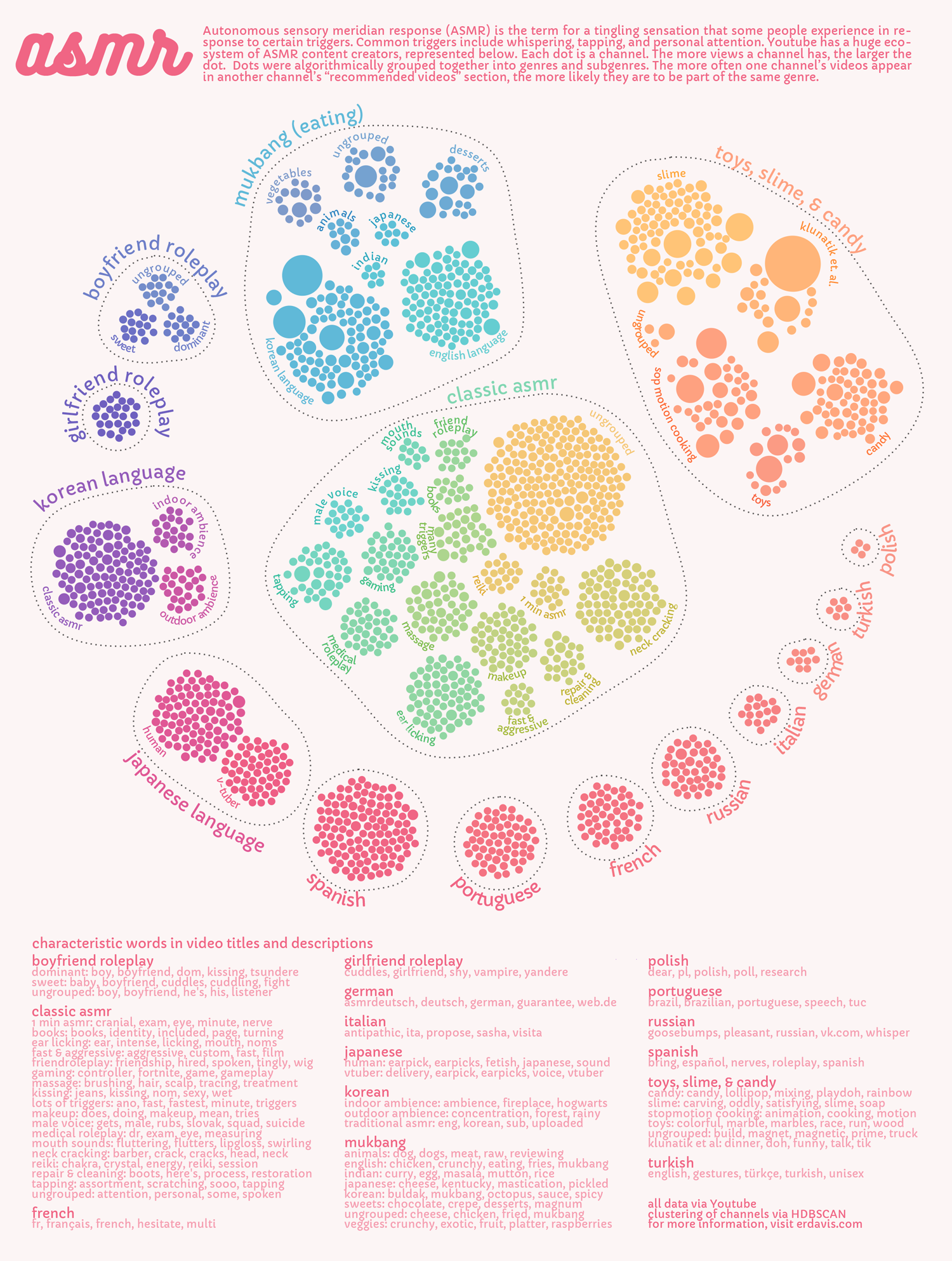
I learned a few fun things from this map:
- The most popular ASMR videos aren’t what I considered “classic” ASMR. Instead, they’re either eating-related or slime-related. Wouldn’t be surprised if kids drove a lot of the popularity there.
- Content is strongly divided by language. Most of the European language videos are quite similar to the Classic ASMR genre in terms of content. However, they only tend to be recommended amongst each other.
- Japanese content showed the clearest subgenre divide of all of them: nearly half of videos are hosted by animated characters (vtubers) and not humans
- Korean-language ASMR contains a huge “calming ambience” community that’s well divided between indoor ambience (crackling fires, pages turning) and outdoor ambience (rain, waves, wind)
ASMR videos
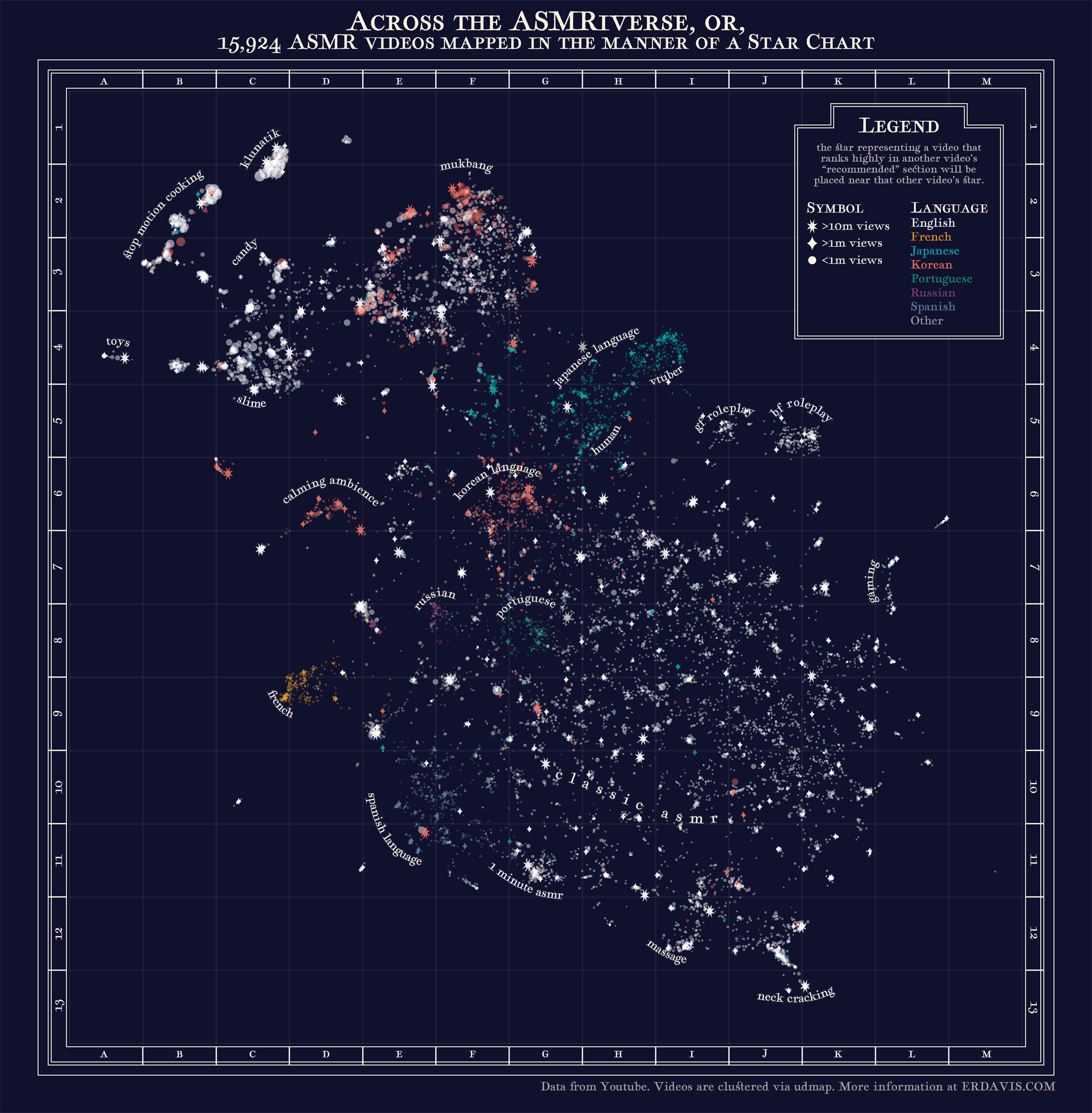
In the process of creating the chart above, I gathered information on how more than 15,000 individual ASMR videos are related to one another. It would be a shame not to map that, as well.
Here, I chose an entirely different aesthetic: vintage star map. I was inspired by the work of Eleanor Lutz, and took my palette directly from her Constellations Around the World project.
My own ASMR habit
For transparency I should come clean about how much and how often I watch ASMR videos. I exported my watch history via Google Takeout, filtered it down to just those creators that appeared in my ASMR list, and plotted it. I seem to have cleared my Youtube watch history in late 2020, so the following data covers just 2021.
It’s a little Ninja Turtle-ish, but I stuck with the same color palette as the first viz for continuity.

These were my most-watched ASMR channels. Seems like there might be a pattern… (I like getting massages but it’s $$$ so I watch other people get them instead please don’t judge me)
| Name | Genre | Subgenre | Watches | Link |
|---|---|---|---|---|
| JadeyWadey 180 | Classic | Massage | 150 | link |
| Latte ASMR | Classic | Ungrouped | 128 | link |
| SemideCoco | Classic | Massage | 109 | link |
| ASMR Twix | Classic | Massage | 100 | link |
| Gentle Whispering ASMR | Classic | Tapping | 74 | link |
| Serein Wu | Classic | Massage | 74 | link |
| TV Shili | Korean | Classic ASMR | 67 | link |
| WhispersRed ASMR | Classic | Massage | 56 | link |
| Little Me Carmie | Classic | Massage | 42 | link |
| emvy ASMR | Classic | Massage | 40 | link |
And my most commonly watched videos. I do like re-watching the same one to have a sort of comforting familiarity in the background.
| Title | Channel | Watches | Genre | Subgenre | Link |
|---|---|---|---|---|---|
| Resurfacing Acne Skin Peel & Guided Meditation for Deep Relaxation | Jadeywadey180 | JadeyWadey 180 | 13 | Classic | Massage | link |
| @Teni Panosian Facial for Uneven Texture + Clogged Pores & Deep Relaxing Sound Bath | JadeyWadey 180 | 12 | Classic | Massage | link |
| ASMR Tingly False Eyelash Shop | Latte ASMR | 12 | Classic | Ungrouped | link |
| [ASMR] Relaxing Crystal Scalp Check with Sticks, Arm & Leg Massage (Real Person, Chakras & Reiki) | SemideCoco | 9 | Classic | Massage | link |
| Sleep With Good Mood ASMR | Latte ASMR | 9 | Classic | Ungrouped | link |
| Clean Skincare Only Holistic Facial & VERY Relaxing Meditation Massage {ASMR} | JadeyWadey 180 | 7 | Classic | Massage | link |
| Healing Pamper Night ASMR | Latte ASMR | 7 | Classic | Ungrouped | link |
| Acne Facial: Brighten Blemishes, Dark Spots + Deep Relaxation | Jadeywadey180 | JadeyWadey 180 | 6 | Classic | Massage | link |
| ASMR Spa Facial {Brighten Dark Spots, Cupping, Dermaplaning, Sleep Meditation} MUST WATCH! | JadeyWadey 180 | 6 | Classic | Massage | link |
| ASMR Steam Facial w/ Oil Gua Sha Massage | WhispersRed ASMR | 6 | Classic | Massage | link |
| Hormonal Acne + Ice Pick Scars + Blackheads Deep Detox Facial {Her first facial ever!} | JadeyWadey 180 | 6 | Classic | Massage | link |
How I did it
I want to try something a bit different for this “How I did it” section, and focus more on my visualization process and less on the data gathering and analysis.
The technical bit
First, the absolute basics on the technical aspects:
- All data was gathered via Youtube API.
- My first pass was to simply search for channels with “ASMR” in the name and grab all their top ASMR videos.
- For each of those ASMR videos, I found the top related videos.
- From those related videos I found a new list of ASMR channels. I then got all their top ASMR videos.
- Then I repeated steps b and c until each cycle was bringing in fewer and fewer new ASMR channels/my patience ran low.
- I then created a matrix to show how related each channel was to every other channel
- Roughly, if a video was highly ranked in the “related videos” results of another video, it scored a lot of points. If it was low-ranked, it scored just a few points.
- Then, I added up how many points each channel’s videos scored on every other channel’s videos. This is a lot easier to express in a bit of R than English!
related <- read.csv("related_videos.csv")
#find which page (of 5 items) each result lands on
related$score <- ceiling(related$resultorder/5)
#weight earlier results higher than later results
related$score <- 100/(3^(related$score -1))
#sum it all up
related <- related %>% group_by(origChannel, relatedChannel) %>%
summarize(score=sum(score))
- I exported that matrix and hopped over to Python. Long story short, I was working on a similar project with an enormous dataset, and Python processed it faster than R. I reused that Python code here, even though it wasn’t necessary.
- In Python, I used the HDBSCAN algorithm to find large clusters of related channels. After playing around with the parameters and reviewing the results, I found a setting that produced 12 clusters, which became my genres.
- I then exported sub-matrices containing just the channels within a particular genre. I fed each submatrix back into HDBSCAN to partition it further into sub-genres.
- At this level, not every video made it into a subgenre. Many videos were widely connected to many other videos, and so didn’t neatly fit into just one category. These are the “ungrouped” bubbles in the map.
- To gather words to summarize each subgenre, I translated the titles and descriptions of each video into English. I then fed that all into the log-likelihood algorithm to detect words that were most strongly associated with each subgenre.
- When I only have a few “documents”, I like this log-likelihood method a lot better than the classic TF-IDF. If a word appears in every document, it won’t score at all in TF-IDF. This makes sense if you’re looking at thousands of documents. If you’re only looking at a few dozen, most of which have a lot of overlap, log-like does a much better job.
- I plotted each subcluster in Gephi to maintain the relationship of each channel within a subgenre (which plain old circle packing wouldn’t necessarily do). I then hand-arranged each subgenre within its genre in Illustrator, using a Gephi map of just the genres as reference. I exported this to Photoshop to add labels and frills, since it’s what I’m most comfortable using.
- For the star map, I exported a matrix of how every video related to every other video. That I fed into the udmap algorithm, which reduced my 15000×15000 matrix to a 15000×2 one that could be nicely mapped in the Cartesian plane. This was plotted in R and fancied up in Photoshop.
The not so technical bit
This project has been cooking in one form or another for at least 3 years. Getting the data was a giant pain in the butt due to Google’s stingy Youtube API limits (100 searches a day? Get outta here), but at least it gave me a LOT of time to think about aesthetics.
When I saw Wendy Shijia’s pastel maps, I knew I wanted to create a pastel data viz. It hit me that this ASMR project was perfect for it, and from there the overall feel was never in any doubt.
The exact color palette was difficult to nail down–I went through a bunch of iterations before modifying a palette I’d previously used for a work project.

The genesis of the circle idea came, I think, from Amelia Wattenberger’s Github repo visualizations.
I always knew I wanted a layout of circles gathered into groups. I could have done a traditional network diagram showing the links between nodes, but those tend to end up being unreadable hairballs. The Github repo visualizations showed one way that nested circles could look beautiful without much else on the page.
I also loved the aesthetics of the following:
Finally, I’m really excited about the fonts I used. I can be kinda lazy about fonts, defaulting to my favorite (Futura) for just about everything. This project, though, called for something friendly and roundish. A quick Google of “friendly typefaces” brought up Bukhari Script, which I used for the title, and Capriola, which I used for the text. Rarely have I ever found perfect fonts so quickly! And they were both free!
The star map
While I was pretty set on having a circle-y pastel visualization, I was also really drawn to the idea of mapping the data as a faux star chart. I’m not 100% sure where that idea came from, but I wouldn’t be surprised if it was this tweet:
Initially, I considered visualization the same channel-level data twice in both styles, but realized it made a ton more sense to do the individual videos as the star chart.
I googled “vintage star charts” to provide the overall aesthetic, and this came together quite a lot quicker than the pastel viz.

One thing I wanted to add was a hint of color among the stars, and chose to visualize video language that way. I think it adds a bit more depth and dynamism to an otherwise monochrome viz.
The colors themselves I got from Eleanor Lutz, who published an amazing chart of constellations (and provided her carefully selected palette, which saved me a ton of work!)
I’m also excited about the font in this piece. I wanted something vintage feeling, and the Geographica Hand font worked perfectly. Fun fact: I’m pretty sure this is the first typeface I’ve ever paid money for, and it was worth it.
In summary, to design my visualizations I often have a very specific idea in mind that I gradually work towards with the data. That idea is frequently seeded by Twitter, in particular–I almost use it like a better Pinterest, and have a huge catalogue of bookmarked tweets that contain some seed of inspiration. Thank you to all those other visualizers out there for putting out such cool work!
Discover more from Data Stuff
Subscribe to get the latest posts sent to your email.
Hi Erin. I also listen to ASMR a lot; my first bookmark on Chrome is a specific ASMR that I listen to all the time. You’re also right in that they’re… a bit embarrassing to admit…?
Always appreciate the combination of technical details + easy-to-digest visuals in your posts. I feel like unsupervised learning projects like these can be more difficult to formulate than supervised ones, as in that you have to choose the right question to answer. But you’ve done a stellar job in carefully thinking about the question and the right way to execute it.
I was looking for resources online to make an ASMR related project myself and found yours. I just wanted to say that it’s really cool and I was just wondering if you saved the dataset and you would be willing to share it. I am personally a Gibi ASMR addict, so I will definitely dive into her long time analytics but I wanted to do something with the broader community too
Sure! see here: https://gist.github.com/erdavis1/a1004a941f5859da87eb86303da53393